In the first post of this series, I have outlined the importance of having a proper operational framework in place before starting any talk of information-theoretic quantities. It is, however, a good idea to pin down even provisionally the kind of information-theoretic quantity one hopes to distill out of the operational formulation. This will be the topic of this post, and the starting point will be the paper by Carl Bergstrom and Martin Rosvall on the “transmission sense of information.”
Let me start by quoting the abstract of the paper for the common objections against applying information-theoretic ideas to biology:
Biologists think in terms of information at every level of investigation. Signaling pathways transduce information, cells process information, animal signals convey information. Information flows in ecosystems, information is encoded in the DNA, information is carried by nerve impulses. In some domains the utility of the information concept goes unchallenged: when a brain scientist says that nerves transmit information, nobody balks. But when geneticists or evolutionary biologists use information language in their day-to-day work, a few biologists and many philosophers become anxious about whether this language can be justified as anything more than facile metaphor.
The key claim of Bergstrom and Rosvall is that, by focusing on what they refer to as the transmission sense of information, it is possible to avoid the two pitfalls of mutual information, namely the “shallow” notion of correlation and the so-called parity thesis. In doing so, they emphasize the importance of operational notions in information theory “by taking the viewpoint of a communications engineer and focusing on the decision problem of how information is to be packaged for transport.” While this recognition of the importance of operationalization is not common in biology, I still think that it misses an important point: The relevant decision problem is not that of a communications engineer, it is that of a control engineer, whose primary aim to ensure reliable transmission of the global constraints (formal causes) governing the unfolding of phenotypes (starting with development and continuing on through the organism’s lifetime). In other words, the meaning and use (i.e., the semantics and the pragmatics) of the genome are primary, the symbolic packaging (the syntax) of the genome is secondary. This will be the subject of future posts. Here, my goal is more modest — a critical reconsideration of the Bergstrom and Rosvall paper and an alternative proposal to use directed information, rather than mutual information.
 on
on  . If
. If  with respect to the Lebesgue measure, i.e.,
with respect to the Lebesgue measure, i.e., 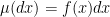 , then we can use the (overdamped) continuous-time Langevin dynamics, governed by the Ito stochastic differential equation (SDE)
, then we can use the (overdamped) continuous-time Langevin dynamics, governed by the Ito stochastic differential equation (SDE) 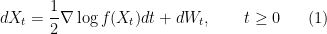
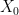 is generated according to some probability law
is generated according to some probability law 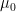 , and
, and  is the standard
is the standard  -dimensional Brownian motion. Let
-dimensional Brownian motion. Let 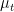 denote the probability law of
denote the probability law of  . Then, under appropriate regularity conditions on
. Then, under appropriate regularity conditions on  , then
, then 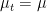 for all
for all  .
.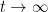 — in fact, it is often possible to show that there exists a constant
— in fact, it is often possible to show that there exists a constant 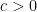 that depends only on
that depends only on 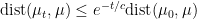
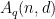 denote the size of the largest code over a
denote the size of the largest code over a  -ary alphabet that has blocklength
-ary alphabet that has blocklength  and minimum distance
and minimum distance 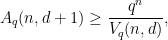
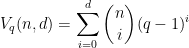
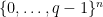 . The usual way of arriving at the GV bound is through a greedy construction: pick an arbitrary codeword
. The usual way of arriving at the GV bound is through a greedy construction: pick an arbitrary codeword  , then keep adding codewords that are at Hamming distance of at least
, then keep adding codewords that are at Hamming distance of at least 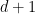 from all codewords that have already been picked. When this procedure terminates, the complement of the union of the Hamming balls of radius
from all codewords that have already been picked. When this procedure terminates, the complement of the union of the Hamming balls of radius 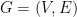 be an undirected graph. A set
be an undirected graph. A set 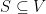 of vertices is called independent if no two vertices in
of vertices is called independent if no two vertices in  are connected by an edge. The independence number of
are connected by an edge. The independence number of  , denoted by
, denoted by 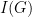 , is the cardinality of the largest independent set. The following lemma is folklore in graph theory:
, is the cardinality of the largest independent set. The following lemma is folklore in graph theory: -regular, i.e., every vertex has exactly
-regular, i.e., every vertex has exactly 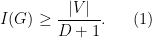
 be a maximal independent set. Any vertex
be a maximal independent set. Any vertex 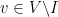 is connected by an edge to at least one
is connected by an edge to at least one 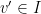 , because otherwise
, because otherwise  would have to be included in
would have to be included in 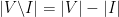 edges with one vertex in
edges with one vertex in 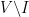 . On the other hand, because
. On the other hand, because 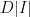 such edges. This means that
such edges. This means that 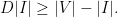

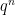 vertices, and each vertex has degree
vertices, and each vertex has degree 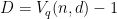 . Moreover, there is a one-to-one correspondence between independent sets of vertices and
. Moreover, there is a one-to-one correspondence between independent sets of vertices and  . The bound
. The bound 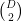 edges), the lower bound
edges), the lower bound 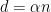 for some
for some 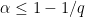 and replace exact combinatorial bounds by entropy bounds.
and replace exact combinatorial bounds by entropy bounds.