Machine learning is about enabling computers to improve their performance on a given task as they get more data. Can we express this intuition quantitatively using information-theoretic techniques? In this post, I will discuss a classic paper by David Haussler, Michael Kearns, and Robert Schapire that (to the best of my knowledge) took the first step in this direction. In this post, I will describe some of their results, recast in a more explicitly information-theoretic way.
We will stick to the setting of binary classification: we have a feature space 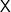
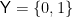



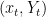
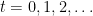

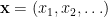
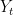
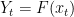

The learning agent receives the training data sequentially: at each time 

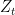

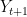
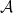




![\displaystyle e_{{\bf x}}({\mathcal A},t) = Q\big[\widehat{Y}_t \neq Y_t\big] \equiv Q\big[a_t(Z^{t-1},x_t) \neq Y_t\big].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%2Ct%29+%3D+Q%5Cbig%5B%5Cwidehat%7BY%7D_t+%5Cneq+Y_t%5Cbig%5D+%5Cequiv+Q%5Cbig%5Ba_t%28Z%5E%7Bt-1%7D%2Cx_t%29+%5Cneq+Y_t%5Cbig%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
We will refer to the function 

How can we measure the learner’s progress? Let’s write out the causal ordering of all the random variables generated in the process of learning:
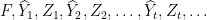
Here, 
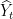
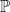
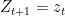

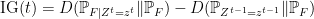
It’s not hard to see that 


![\displaystyle {\mathbb E} [{\rm IG}(t)] = I(F; Z_t | Z^{t-1}),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D+%5B%7B%5Crm+IG%7D%28t%29%5D+%3D+I%28F%3B+Z_t+%7C+Z%5E%7Bt-1%7D%29%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
the conditional mutual information between
To that end, let us first observe that, at time

This set is known in learning theory as the version space at time 


![\displaystyle {\mathbb P}[F \in {\mathcal E}|Z^t=z^t] = Q({\mathcal E} | {\mathcal V}_t) = \frac{Q({\mathcal E} \cap {\mathcal V}_t)}{Q({\mathcal V}_t)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%7B%5Cmathbb+P%7D%5BF+%5Cin+%7B%5Cmathcal+E%7D%7CZ%5Et%3Dz%5Et%5D+%3D+Q%28%7B%5Cmathcal+E%7D+%7C+%7B%5Cmathcal+V%7D_t%29+%3D+%5Cfrac%7BQ%28%7B%5Cmathcal+E%7D+%5Ccap+%7B%5Cmathcal+V%7D_t%29%7D%7BQ%28%7B%5Cmathcal+V%7D_t%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
This implies, in particular, that

and therefore that

where 



Note, by the way, that since 
![\displaystyle \xi_t = \frac{Q({\mathcal V}_t \cap {\mathcal V}_{t-1})}{Q({\mathcal V}_{t-1})} = {\mathbb P}[F \in {\mathcal V}_t | F \in {\mathcal V}_{t-1}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Cxi_t+%3D+%5Cfrac%7BQ%28%7B%5Cmathcal+V%7D_t+%5Ccap+%7B%5Cmathcal+V%7D_%7Bt-1%7D%29%7D%7BQ%28%7B%5Cmathcal+V%7D_%7Bt-1%7D%29%7D+%3D+%7B%5Cmathbb+P%7D%5BF+%5Cin+%7B%5Cmathcal+V%7D_t+%7C+F+%5Cin+%7B%5Cmathcal+V%7D_%7Bt-1%7D%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Consequently,

We are going to use binary algorithms, so the units of all information quantities are bits.
Now let’s get down to business. Following Haussler et al., we will consider the following two learning algorithms:
- The Bayes algorithm
: at time
into two disjoint subsets
and then predicts
The Bayes algorithm is optimal in the sense that it minimizes the probability of incorrectly predicting
will not, in general, be an element of
- The Gibbs algorithm
: at time
and predicts
The Gibbs algorithm is suboptimal, but, unlike the Bayes algorithm, the function


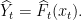
Now let’s analyze their learning curves:
- The Bayes algorithm will make a mistake whenever
, i.e., whenever
. Indeed, using the fact that, by definition of the version space,
we have
Thus, if
, and so
. On the other hand, if
, the Bayes algorithm will be correct:
. Finally, if
, then the Bayes algorithm will make a mistake with probability
. Therefore,
where we have defined the function
- The Gibbs algorithm will make a mistake whenever
is not in the version space
. Since
, we have

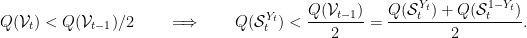
![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Bayes},t) = {\mathbb E} [\vartheta(1/2-\xi_t)],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D+%5B%5Cvartheta%281%2F2-%5Cxi_t%29%5D%2C+%09&bg=ffffff&fg=000000&s=0&c=20201002)
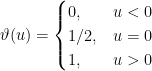
![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Gibbs},t) = {\mathbb P}\left[\widehat{F}_t \not\in {\mathcal V}_t\right] = {\mathbb E} [1-\xi_t].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Gibbs%7D%2Ct%29+%3D+%7B%5Cmathbb+P%7D%5Cleft%5B%5Cwidehat%7BF%7D_t+%5Cnot%5Cin+%7B%5Cmathcal+V%7D_t%5Cright%5D+%3D+%7B%5Cmathbb+E%7D+%5B1-%5Cxi_t%5D.+%09&bg=ffffff&fg=000000&s=0&c=20201002)
Before stating and proving the main result, we need to collect some preliminary facts. First of all, the volume ratio 


![{g : [0,1] \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bg+%3A+%5B0%2C1%5D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathbb E} [g(\xi_t)] = {\mathbb E} [\xi_t g(\xi_t) + (1-\xi_t)g(1-\xi_t)] \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cmathbb+E%7D+%5Bg%28%5Cxi_t%29%5D+%3D+%7B%5Cmathbb+E%7D+%5B%5Cxi_t+g%28%5Cxi_t%29+%2B+%281-%5Cxi_t%29g%281-%5Cxi_t%29%5D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
(the proof is by conditioning on
Theorem 1 We have the following bounds for the Bayes and the Gibbs algorithms:
where
is the inverse of the binary entropy function
.


Remark 1 Equation (2) shows that the error probability of the Bayes algorithm at time
Proof: We start by obtaining the following alternative expressions for the error probabilities of the two algorithms, as well as for the expected information gain:
Using (1) with 
![\displaystyle I(F; Z_t | Z^{t-1}) = {\mathbb E} [-\log \xi_t] = -{\mathbb E} [\xi_t \log \xi_t + (1-\xi_t) \log (1-\xi_t)] = {\mathbb E} [h(\xi_t)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09%09I%28F%3B+Z_t+%7C+Z%5E%7Bt-1%7D%29+%3D+%7B%5Cmathbb+E%7D+%5B-%5Clog+%5Cxi_t%5D+%3D+-%7B%5Cmathbb+E%7D+%5B%5Cxi_t+%5Clog+%5Cxi_t+%2B+%281-%5Cxi_t%29+%5Clog+%281-%5Cxi_t%29%5D+%3D+%7B%5Cmathbb+E%7D+%5Bh%28%5Cxi_t%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
This shows, in particular, that the average information gain due to receiving another training sample is no more than one bit.
With 
![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Bayes},t) = {\mathbb E} [\vartheta(1/2-\xi_t)] = {\mathbb E} [\xi_t \vartheta(1/2-\xi_t) + (1-\xi_t) \vartheta(\xi_t - 1/2)] = {\mathbb E}\left[\min\{\xi_t,1-\xi_t\}\right],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D+%5B%5Cvartheta%281%2F2-%5Cxi_t%29%5D+%3D+%7B%5Cmathbb+E%7D+%5B%5Cxi_t+%5Cvartheta%281%2F2-%5Cxi_t%29+%2B+%281-%5Cxi_t%29+%5Cvartheta%28%5Cxi_t+-+1%2F2%29%5D+%3D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cmin%5C%7B%5Cxi_t%2C1-%5Cxi_t%5C%7D%5Cright%5D%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
where we have used the fact that, for any ![{u \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bu+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Another way to arrive at this expression is by using the following fact: Suppose we have a biased coin with probability of heads equal to 
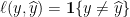



Finally, with 
![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Gibbs},t) = {\mathbb E} [1-\xi_t] = 2{\mathbb E} [\xi_t(1-\xi_t)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%09%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Gibbs%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D+%5B1-%5Cxi_t%5D+%3D+2%7B%5Cmathbb+E%7D+%5B%5Cxi_t%281-%5Cxi_t%29%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Again, if we consider the problem of guessing the outcome of tossing a 



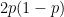
We will also use the following chain of easy-to-prove inequalities: for any

We start by proving the lower bound, Equation (2). First, note that, for any
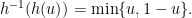
Moreover, the function ![{h^{-1} : [0,1] \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bh%5E%7B-1%7D+%3A+%5B0%2C1%5D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle e_{{\bf x}}({\mathcal A}^{\rm Bayes},t) = {\mathbb E}\left[\min\{\xi_t,1-\xi_t\}\right] = {\mathbb E} [h^{-1}(h(\xi_t))] \ge h^{-1}\left({\mathbb E} [h(\xi_t)]\right) =h^{-1}\left(I(F;Z_t|Z^{t-1})\right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09e_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2Ct%29+%3D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Cmin%5C%7B%5Cxi_t%2C1-%5Cxi_t%5C%7D%5Cright%5D+%3D+%7B%5Cmathbb+E%7D+%5Bh%5E%7B-1%7D%28h%28%5Cxi_t%29%29%5D+%5Cge+h%5E%7B-1%7D%5Cleft%28%7B%5Cmathbb+E%7D+%5Bh%28%5Cxi_t%29%5D%5Cright%29+%3Dh%5E%7B-1%7D%5Cleft%28I%28F%3BZ_t%7CZ%5E%7Bt-1%7D%29%5Cright%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
The upper bound, Equation (3), follows by taking 

Now let’s see what happens when we have to do this over and over again: at each time 

for each 

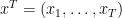
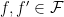

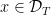
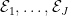



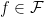


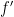

Consequently,
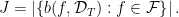
For any subset 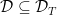


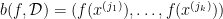



for all 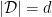

Now we are ready to state and prove the following:

Proof: We have
![\displaystyle \begin{array}{rcl} \bar{e}_{{\bf x}}({\mathcal A}^{\rm Bayes},T) &\le& \bar{e}_{{\bf x}}({\mathcal A}^{\rm Gibbs},T)\\ &\le& \frac{1}{2T}\sum^T_{t=1} {\mathbb E} [-\log \xi_t] \\ &=& \frac{1}{2T}\sum^T_{t=1} {\mathbb E}\left[\log \frac{Q({\mathcal V}_{t-1})}{Q({\mathcal V}_t)}\right] \\ &=& \frac{1}{2T}{\mathbb E}\left[\log \frac{Q({\mathcal V}_0)}{Q({\mathcal V}_T)}\right] \\ &=& \frac{1}{2T}{\mathbb E}\left[\log \frac{1}{Q({\mathcal V}_T)}\right]. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09%09%5Cbar%7Be%7D_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Bayes%7D%2CT%29+%26%5Cle%26+%5Cbar%7Be%7D_%7B%7B%5Cbf+x%7D%7D%28%7B%5Cmathcal+A%7D%5E%7B%5Crm+Gibbs%7D%2CT%29%5C%5C+%09%09%26%5Cle%26+%5Cfrac%7B1%7D%7B2T%7D%5Csum%5ET_%7Bt%3D1%7D+%7B%5Cmathbb+E%7D+%5B-%5Clog+%5Cxi_t%5D+%5C%5C+%09%09%26%3D%26+%5Cfrac%7B1%7D%7B2T%7D%5Csum%5ET_%7Bt%3D1%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BQ%28%7B%5Cmathcal+V%7D_%7Bt-1%7D%29%7D%7BQ%28%7B%5Cmathcal+V%7D_t%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+%5Cfrac%7B1%7D%7B2T%7D%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BQ%28%7B%5Cmathcal+V%7D_0%29%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+%5Cfrac%7B1%7D%7B2T%7D%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D.+%09%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
From the definition of the version spaces, it is immediate that 


![\displaystyle \begin{array}{rcl} {\mathbb E}\left[\log \frac{1}{Q({\mathcal V}_T)}\right] &=& \sum^J_{j=1} {\mathbb E}\left[{\bf 1}\{F \in {\mathcal E}_j\}\log\frac{1}{Q({\mathcal V}_T)}\right] \\ &=& \sum^J_{j=1} {\mathbb E}\left[{\bf 1}\{F \in {\mathcal E}_j\}\log\frac{1}{Q({\mathcal E}_j)}\right] \\ &=& -\sum^J_{j=1} Q({\mathcal E}_j) \log Q({\mathcal E}_j). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09%09%7B%5Cmathbb+E%7D%5Cleft%5B%5Clog+%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D+%26%3D%26+%5Csum%5EJ_%7Bj%3D1%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%7B%5Cbf+1%7D%5C%7BF+%5Cin+%7B%5Cmathcal+E%7D_j%5C%7D%5Clog%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+V%7D_T%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+%5Csum%5EJ_%7Bj%3D1%7D+%7B%5Cmathbb+E%7D%5Cleft%5B%7B%5Cbf+1%7D%5C%7BF+%5Cin+%7B%5Cmathcal+E%7D_j%5C%7D%5Clog%5Cfrac%7B1%7D%7BQ%28%7B%5Cmathcal+E%7D_j%29%7D%5Cright%5D+%5C%5C+%09%09%26%3D%26+-%5Csum%5EJ_%7Bj%3D1%7D+Q%28%7B%5Cmathcal+E%7D_j%29+%5Clog+Q%28%7B%5Cmathcal+E%7D_j%29.+%09%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
We can recognize the quantity in the last line as the Shannon entropy of the index 
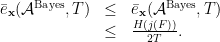
Now, since 

The claimed bound (6) follows.
If 
Corollary 3

