In the first post of this series, I have outlined the importance of having a proper operational framework in place before starting any talk of information-theoretic quantities. It is, however, a good idea to pin down even provisionally the kind of information-theoretic quantity one hopes to distill out of the operational formulation. This will be the topic of this post, and the starting point will be the paper by Carl Bergstrom and Martin Rosvall on the “transmission sense of information.”
Let me start by quoting the abstract of the paper for the common objections against applying information-theoretic ideas to biology:
Biologists think in terms of information at every level of investigation. Signaling pathways transduce information, cells process information, animal signals convey information. Information flows in ecosystems, information is encoded in the DNA, information is carried by nerve impulses. In some domains the utility of the information concept goes unchallenged: when a brain scientist says that nerves transmit information, nobody balks. But when geneticists or evolutionary biologists use information language in their day-to-day work, a few biologists and many philosophers become anxious about whether this language can be justified as anything more than facile metaphor.
The key claim of Bergstrom and Rosvall is that, by focusing on what they refer to as the transmission sense of information, it is possible to avoid the two pitfalls of mutual information, namely the “shallow” notion of correlation and the so-called parity thesis. In doing so, they emphasize the importance of operational notions in information theory “by taking the viewpoint of a communications engineer and focusing on the decision problem of how information is to be packaged for transport.” While this recognition of the importance of operationalization is not common in biology, I still think that it misses an important point: The relevant decision problem is not that of a communications engineer, it is that of a control engineer, whose primary aim to ensure reliable transmission of the global constraints (formal causes) governing the unfolding of phenotypes (starting with development and continuing on through the organism’s lifetime). In other words, the meaning and use (i.e., the semantics and the pragmatics) of the genome are primary, the symbolic packaging (the syntax) of the genome is secondary. This will be the subject of future posts. Here, my goal is more modest — a critical reconsideration of the Bergstrom and Rosvall paper and an alternative proposal to use directed information, rather than mutual information.
If you are not familiar with directed information, I recommend two old posts of mine (one, two) for the basic background. Briefly, the notion of directed information was proposed by Jim Massey in 1990 in order to analyze systems with feedback by focusing on functional, rather than statistical, dependencies:
… probabilistic dependence is quite distinct from causal dependence. Whether
causes
or
This point will be important to us later on.
1. The model
We will consider a very simple model involving the temporal evolution of genotypes and phenotypes in a random environment. We will work in discrete time, using 

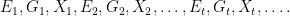
Let us consider what happens in 
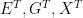
The factorization of the joint distribution in (1) encodes some important assumptions, which we need to spell out:
- The genotype and the environment are modeled by two discrete-time stochastic processes. Notice that the environment is not necessarily Markovian, but the genome process is a Markov process in a random environment (i.e., at each time
, the genome
is conditionally independent of
and
given
and
). This is a very simple model of asexual reproduction, and the process distribution of
models mutations (through stochastic dependence of
- The phenotype at
Again, I need to emphasize that this is a very simple model (see, e.g., the work of Rivoire and Leibler) that does not account for various feedback mechanisms by which the organisms can act on their environments, such as niche construction.
2. The lack of directivity and the parity thesis
Bergstrom and Rosvall consider what happens at each 

- Mutual information is a “shallow” notion of statistical correlation (in the words of Massey, it has no inherent directivity). Indeed, since the mutual information is symmetric, we have
, and this symmetry runs counter to the central dogma (no flow of information from proteins to genes). In fact, we can also include the environment and consider
, which runs into the same issues. There is also the related objection that, whatever information there is in the genes, it is semantic in some sense, whereas the semantic aspects are notably absent from Shannon’s theory.
- Once we bring the environment into the picture, we also have to deal with the so-called “parity thesis:” In the terminology of Bayes networks, the random triple
are mutually independent, and
is conditionally dependent on both of them —
. As a DAG, this Bayes network is symmetric with respect to
I agree with Bergstrom and Rosvall that these objections provide a strong argument against using mutual information in this context. However, this does not mean that there is no alternative information-theoretic construct that is free of the drawbacks of the mutual information. I claim that one has to use directed information instead. This should not be surprising, since we are in fact trying to capture functional, rather than statistical, dependencies. So, let us then compute the directed informations 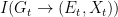
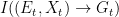



and are given by
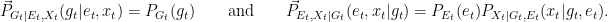
With these, we can compute the corresponding directed informations:
![\displaystyle \begin{array}{rcl} I(G_t \rightarrow (E_t,X_t)) &=& D(P_{G_t,E_t,X_t}\|\vec{P}_{G_t|E_t,X_t} \times P_{E_t,X_t}) \\ &=& {\mathbf E}\left[\log \frac{P_{G_t,E_t,X_t}}{\vec{P}_{G_t|E_t,X_t} P_{E_t,X_t}}\right] \\ &=& {\mathbf E}\left[\log \frac{P_{G_t,E_t,X_t}}{P_{G_t} P_{E_t,X_t}} \right] \\ &=& I(G_t; E_t,X_t), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09I%28G_t+%5Crightarrow+%28E_t%2CX_t%29%29+%26%3D%26+D%28P_%7BG_t%2CE_t%2CX_t%7D%5C%7C%5Cvec%7BP%7D_%7BG_t%7CE_t%2CX_t%7D+%5Ctimes+P_%7BE_t%2CX_t%7D%29+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG_t%2CE_t%2CX_t%7D%7D%7B%5Cvec%7BP%7D_%7BG_t%7CE_t%2CX_t%7D+P_%7BE_t%2CX_t%7D%7D%5Cright%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG_t%2CE_t%2CX_t%7D%7D%7BP_%7BG_t%7D+P_%7BE_t%2CX_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%3D%26+I%28G_t%3B+E_t%2CX_t%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
so this equals just the mutual information between 
![\displaystyle \begin{array}{rcl} I((E_t,X_t) \rightarrow G_t) &=& D(P_{E_t,X_t,G_t} \| \vec{P}_{E_t,X_t|G_t} \times P_{G_t}) \\ &=& {\mathbf E}\left[\log \frac{P_{E_t,X_t,G_t}}{\vec{P}_{E_t,X_t|G_t} P_{G_t}} \right] \\ &=& {\mathbf E}\left[\log \frac{P_{E_t,X_t,G_t}}{P_{E_t}P_{X_t|G_t,E_t} P_{G_t}} \right] \\ &=& {\mathbf E}\left[\log \frac{P_{E_t,X_t,G_t}}{P_{E_t,X_t,G_t}} \right] \\ &\equiv& 0. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09I%28%28E_t%2CX_t%29+%5Crightarrow+G_t%29+%26%3D%26+D%28P_%7BE_t%2CX_t%2CG_t%7D+%5C%7C+%5Cvec%7BP%7D_%7BE_t%2CX_t%7CG_t%7D+%5Ctimes+P_%7BG_t%7D%29+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BE_t%2CX_t%2CG_t%7D%7D%7B%5Cvec%7BP%7D_%7BE_t%2CX_t%7CG_t%7D+P_%7BG_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BE_t%2CX_t%2CG_t%7D%7D%7BP_%7BE_t%7DP_%7BX_t%7CG_t%2CE_t%7D+P_%7BG_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BE_t%2CX_t%2CG_t%7D%7D%7BP_%7BE_t%2CX_t%2CG_t%7D%7D+%5Cright%5D+%5C%5C+%09%26%5Cequiv%26+0.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Since directed information quantifies causal (or functional), rather than statistical, dependencies, this is to be expected — the genes together with the environment exert causal influence on the phenotype, but the phenotype and the environment cannot exert any causal influence on the genes. Here it may also be useful to recall the conservation law that relates mutual information and directed information:
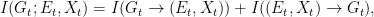
and, since the second term on the right-hand side is identically zero, in this particular instance the mutual information between
The “parity thesis” is more interesting, and it is indeed a subtle issue. It is easy to see that we can interchange the roles of

This is, as I had mentioned earlier, a simple consequence of the collider structure 







Remember, by the way, that in all of the above I have assumed that there is no dependence between the genome and the environment (i.e., genes may undergo mutation, but there is no selection). We can include selection as well, but the resulting mathematics will be a lot more complicated; in particular, we will need to consider so-called causally conditioned directed information, when we condition on the past realizations of 


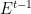
3. The vertical dimension and the transmission sense
Again, let’s follow Bergstrom and Rosvall and simplify things for now by assuming no selection, so 


Thus, we can compute the directed information
![\displaystyle \begin{array}{rcl} I(G^T \rightarrow (E^T,X^T)) &=& {\mathbf E}\left[\log \frac{P_{G^T,E^T,X^T}}{\vec{P}_{G^T|E^T,X^T} \times P_{E^T,X^T}}\right] \\ &=& {\mathbf E}\left[\log \frac{P_{G^T,E^T,X^T}}{P_{G^T}P_{E^T,X^T}}\right] \\ &=& I(G^T; E^T,X^T), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++I%28G%5ET+%5Crightarrow+%28E%5ET%2CX%5ET%29%29+%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG%5ET%2CE%5ET%2CX%5ET%7D%7D%7B%5Cvec%7BP%7D_%7BG%5ET%7CE%5ET%2CX%5ET%7D+%5Ctimes+P_%7BE%5ET%2CX%5ET%7D%7D%5Cright%5D+%5C%5C+%26%3D%26+%7B%5Cmathbf+E%7D%5Cleft%5B%5Clog+%5Cfrac%7BP_%7BG%5ET%2CE%5ET%2CX%5ET%7D%7D%7BP_%7BG%5ET%7DP_%7BE%5ET%2CX%5ET%7D%7D%5Cright%5D+%5C%5C+%26%3D%26+I%28G%5ET%3B+E%5ET%2CX%5ET%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and, once again, 
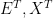


so focusing on the temporal unfolding of genes, proteins, and environments does not rid us of the parity thesis. Since both genes and environments affect the phenotype, this is not surprising at all.
Bergstrom and Rosvall’s resolution is to cut through all of this by focusing on just the genome process 

From the viewpoint of a communications engineer, Equation (2) does indeed describe a communication channel: The environment
Now, uncertainty about what? In order to answer this question, we need to pose an operational interpretation, an optimization problem that our fictitious engineer must solve. And, as I have stressed before, the value of this optimization problem cannot be stated a priori in information-theoretic terms; any such quantity has to be distilled from the nature of the original problem and from the interplay of the source, the channel, and the overall goals. Bergstrom and Rosvall do not give such a formulation, but it is possible to come up with one — see, e.g., the works by Rivoire and Leibler given in the references (I may write a blog post on their work in the future).
I want to close with a critical look at the following quote from the Bergstrom and Rosvall paper:
When information theorists think about coding, they are not thinking about semantic properties. All of the semantic properties are stuffed into the codebook, the interface between source structure and channel structure, which to information theorists is as interesting as a phonebook is to sociologists. When an information theorist says “Tell me how data stream A codes for message set B,” she is not asking you to read her the codebook. She is asking you to tell her about compression, channel capacity, distortion structure, redundancy, and so forth. That is, she wants to know how the structure of the code reflects the statistical properties of the data source and the channel with respect to the decision problem of effectively packaging information for transport.
While the last part is correct (about the structure of the code reflecting the statistics of the source and the channel with respect to the underlying operational criterion), the opening claim about semantics is not entirely accurate. I have touched upon some of these issues in a Twitter thread:
In this thread, I will argue that the conventional wisdom that Shannon’s information theory is all about syntax and not about semantics stems from superficial reading. On the contrary, even his 1948 BSTJ paper is already concerned with syntax, semantics, *and* pragmatics. 1/14
— Maxim Raginsky (@mraginsky) January 29, 2021
I will probably expand that thread into a blog post soon, but here I just want to emphasize the basic nature of the decision problem faced by a communications engineer. The goal is to convey some information about a source 

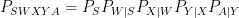
(and here I am simplifying quite a bit and not worrying about time structure, feedback, etc). Of the stochastic kernels making up this factorization, the two things that are not under the control of the system designer are the source probability law 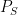
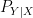



![{{\mathbf E}[c(S,A)]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cmathbf+E%7D%5Bc%28S%2CA%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

It seems that the transmission sense of Bergstrom and Rosvall could pertain to the structure of the channel input and output alphabets and to the distributional properties of 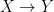

References
- Carl Bergstrom and Martin Rosvall, “The transmission sense of information”
- James Massey, “Causality, feedback, and directed information”
- Robert Cogburn, “Markov Chains in random environments: The case of Markovian environments”
- Olivier Rivoire and Stanislas Leibler, “The value of information for populations in random environments”
- Olivier Rivoire, “Information in models of evolutionary dynamics”
- Howard Pattee, “The physics of symbols: bridging the epistemic cut”
- Sridhar Vembu, Sergio Verdú, and Yossef Steinberg, “The source-channel separation theorem revisited”
- Gérard Battail, “Error-correcting codes and information in biology”
