Larry Wasserman‘s recent post about misinterpretation of p-values is a good reminder about a fundamental distinction anyone working in information theory, control or machine learning should be aware of — namely, the distinction between stochastic kernels and conditional probability distributions.
Roughly speaking, stochastic kernels are building blocks, objects that have to be interconnected in order to instantiate stochastic systems. Conditional probability distributions, on the other hand, arise only when we apply Bayes’ theorem to joint probability distributions induced by these interconnections.
At a very high level of abstraction, we may imagine a space of observations or outcomes  and a space of states or inputs
and a space of states or inputs 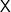 . Each possible state
. Each possible state 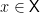 induces a probability distribution over — let’s denote it by
induces a probability distribution over — let’s denote it by 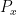 . The interpretation is that if the state is
. The interpretation is that if the state is  , then the probability that we observe an outcome in some set
, then the probability that we observe an outcome in some set 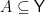 is
is  . Notice that this stipulation has the flavor of a conditional statement: if A then B. Mathematical statisticians (going back to Abraham Wald, and greatly elaborated by Lucien Le Cam and his followers) like to think of the collection
. Notice that this stipulation has the flavor of a conditional statement: if A then B. Mathematical statisticians (going back to Abraham Wald, and greatly elaborated by Lucien Le Cam and his followers) like to think of the collection 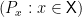 as an experiment that reveals something about the state in through a random observation in . Note that
as an experiment that reveals something about the state in through a random observation in . Note that  is not a set of probability distributions — two distinct ‘s may carry two identical ‘s (which would indicate that these two ‘s are statistically indistinguishable on the basis of observations); or, in the simplest case of a binary state space
is not a set of probability distributions — two distinct ‘s may carry two identical ‘s (which would indicate that these two ‘s are statistically indistinguishable on the basis of observations); or, in the simplest case of a binary state space  , the experiment that has
, the experiment that has  and
and  is different from the one with
is different from the one with  and
and 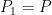 , where
, where  and
and  are two fixed probability distributions on . So perhaps it is better to think about the experiment
are two fixed probability distributions on . So perhaps it is better to think about the experiment 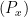 as a function from into
as a function from into 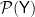 , the space of all probability distributions on . When we impose a measurable structure on the state space as well and then require this function to be sufficiently well-behaved, so that the mapping
, the space of all probability distributions on . When we impose a measurable structure on the state space as well and then require this function to be sufficiently well-behaved, so that the mapping 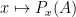 is nice (read: measurable) for any
is nice (read: measurable) for any  , then we have a stochastic kernel.
, then we have a stochastic kernel.
Larry’s point about p-values is as follows: a binary hypothesis testing problem is a binary experiment 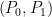 , where
, where 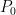 and
and 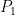 can be thought of as two fixed distributions on some observation space that “explain” the observed outcomes given each hypothesis. If we compute a test statistic
can be thought of as two fixed distributions on some observation space that “explain” the observed outcomes given each hypothesis. If we compute a test statistic 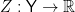 and let
and let  be the realized value of
be the realized value of  , then the p-value (for a two-sided test) is
, then the p-value (for a two-sided test) is
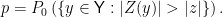
It’s not a conditional probability of anything, but rather the probability a certain event would have if the state were  . In order to have conditioning, all relevant quantities must be instantiated as random variables. Let’s consider an example any information theorist should relate to: a binary symmetric channel.
. In order to have conditioning, all relevant quantities must be instantiated as random variables. Let’s consider an example any information theorist should relate to: a binary symmetric channel.
The ingredients are: the input space 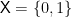 , the output space
, the output space 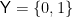 , and the experiment
, and the experiment
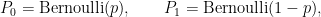
where ![{p \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bp+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is the channel’s crossover probability. We often write the channel transition probabilities suggestively as
is the channel’s crossover probability. We often write the channel transition probabilities suggestively as 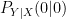 etc., but that is, strictly speaking, incorrect. Until we specify something about the input to the channel, all we have is the experiment , together with a list of possible statements like
etc., but that is, strictly speaking, incorrect. Until we specify something about the input to the channel, all we have is the experiment , together with a list of possible statements like
if the input is , then the probability of observing at the output is 
and the like. If we now say that the input is a random variable  taking values in according to a given distribution
taking values in according to a given distribution 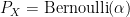 , then we may make conditional probability statements and compute conditional probability distributions
, then we may make conditional probability statements and compute conditional probability distributions 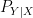 and
and 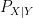 . Of course, in this case it so happens that the conditional probability distribution is already given in terms of the original experiment. But, properly speaking, this conditional object does not exist until we fix
. Of course, in this case it so happens that the conditional probability distribution is already given in terms of the original experiment. But, properly speaking, this conditional object does not exist until we fix  . Even more dramatically, the posterior does not exist at all until we specify , interconnect the source of to the kernel corresponding to the experiment , and start doing what Bayesians would call inverse inference. This distinction between kernel specifications and conditional probability distributions may seem purely notational, but it matters a great deal as soon as feedback enters into the picture.
. Even more dramatically, the posterior does not exist at all until we specify , interconnect the source of to the kernel corresponding to the experiment , and start doing what Bayesians would call inverse inference. This distinction between kernel specifications and conditional probability distributions may seem purely notational, but it matters a great deal as soon as feedback enters into the picture.
The clearest statement on the implications of this distinction has been made by Hans Witsenhausen in his influential paper on separation between estimation and control:
When the control laws have been selected and instrumented, and only then, the control variables (and the state and output variables, and the cost) become random variables, that is, become functionally related to the given random variables (noise, initial state) and therefore become functionally related to the underlying probability space. But to the designer who is still seeking for good control laws and has not made a selection yet, the realizations of control are not even random variables. They are just “random variables to be” of yet uncertain status.
I also recommend a recent paper by Jan Willems on what he terms “open stochastic systems.” It is best to illustrate the main idea of this paper through another example any information theorist should be familiar with: additive white Gaussian noise (AWGN) channel. We are all used to writing it down as

where is the input, 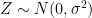 is the additive noise independent of , and
is the additive noise independent of , and  is the output. Of course, this expression tacitly assumes that we have already specified a distribution of the input . One may fix things by writing
is the output. Of course, this expression tacitly assumes that we have already specified a distribution of the input . One may fix things by writing

with the understanding that is some input. But even this is not quite right in view of the above quote from Witsenhausen: is just a placeholder, something waiting to be assigned. Properly speaking, the only “legitimate” random variable here is the Gaussian noise . So Willems suggests thinking instead of the set of all pairs 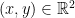 such that
such that

If is now realized as a random input from some distribution , we get back our usual model from (1). However, this new viewpoint is a lot more interesting because it has room for things like causality. Consider, for example, a more complicated arrangement, in which the input taking values in some space is first “modulated” by some nonlinear transformation 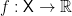 , and then the noise is added to the output of this nonlinear transformation. Then we can represent the overall open system as the set of all pairs
, and then the noise is added to the output of this nonlinear transformation. Then we can represent the overall open system as the set of all pairs  , such that
, such that

Thus, to each specific value of we can associate a random variable
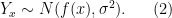
But if we specify  , then things get a lot more interesting: if
, then things get a lot more interesting: if  is not invertible, then the most we can say about
is not invertible, then the most we can say about 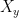 is that
is that

or that is somewhere in the preimage, under , of a Gaussian random variable with mean and variance  . Unless we are in an exceptional situation (e.g., if is one-to-one), it is reasonable to say that (3) expresses a “more complex” statement compared to (2). From this viewpoint, it is more reasonable to say that is the input that causes , and not the other way around. (This way of thinking about causality has, in fact, already found its way into machine learning literature.) The paper of Willems contains a lot more insightful examples and thought-provoking discussion.
. Unless we are in an exceptional situation (e.g., if is one-to-one), it is reasonable to say that (3) expresses a “more complex” statement compared to (2). From this viewpoint, it is more reasonable to say that is the input that causes , and not the other way around. (This way of thinking about causality has, in fact, already found its way into machine learning literature.) The paper of Willems contains a lot more insightful examples and thought-provoking discussion.
So, to summarize: the misunderstanding about conditioning that Larry Wasserman has sought to clear up persists not only in statistics, but also in all other fields involving stochastic systems, such as communications, control, machine learning, etc., and we should always be careful not to fall into this trap.

One thought on “Stochastic kernels vs. conditional probability distributions”